SpringBatch 간단 정리
July 14, 2021
스프링 배치의 장점
- 대용량 데이터 처리에 최적화되어 고성능을 발휘
- 효과적인 로깅, 통계 처리, 트랜잭션 관리 등 재사용 가능한 필수 기능 지원
- 수동으로 처리하지 않도록 자동화
스프링 배치 주의사항
스프링 부트 배치는 스프링 배치를 간편하게 사용 할 수 있게 래핑한 프로젝트입니다. 따라서 스프링 부트 배치와 스프링 배치에 모두에서 다음과 같은 주의사항을 염두해야 한다.
- 데이터를 직접 사용하는 편이 빈번하게 일어나므로 데이터 무결성을 우지하는데 유효성 검사 등의 방어책이 있어야한다.
- 배치 처리 시스템 I/O 사용을 최소화 필요. 잦은 I/O로 데이터베이스 커넥션과 네트워크 비용이 커지면 성능에 영향을 줄 수 있기 때문. 따라서 가능하면 한번에 데이터를 조회하여 메모리에 저장해두고 처리를 한 다음 그결과를 한번에 데이터베이스에 저장하는것이 좋다.
- 일반적으로 같은 서비스에 사용되는 웹 API, 배치, 기타 프로젝트들을 서로 영향을 줍니다. 따라서 배치 처리가 진행되는 동안 다른 프로젝트 요소에 영향을 주는 경우가 없는지 주의를 기울여야한다.
배치 이해하기
배치의 일반적인 시나리오는 다음과 같은 3단계로 이루어진다.
- 읽기(read) : 데이터 저장소(일반적으로 데이터베이스)에서 특정 데이터 레코드를 읽음
- 처리(processing) : 원하는 방식으로 데이터 가공/처리
- 쓰기(write) : 수정된 데이터를 다시 저장소(데이터베이스)에 저장
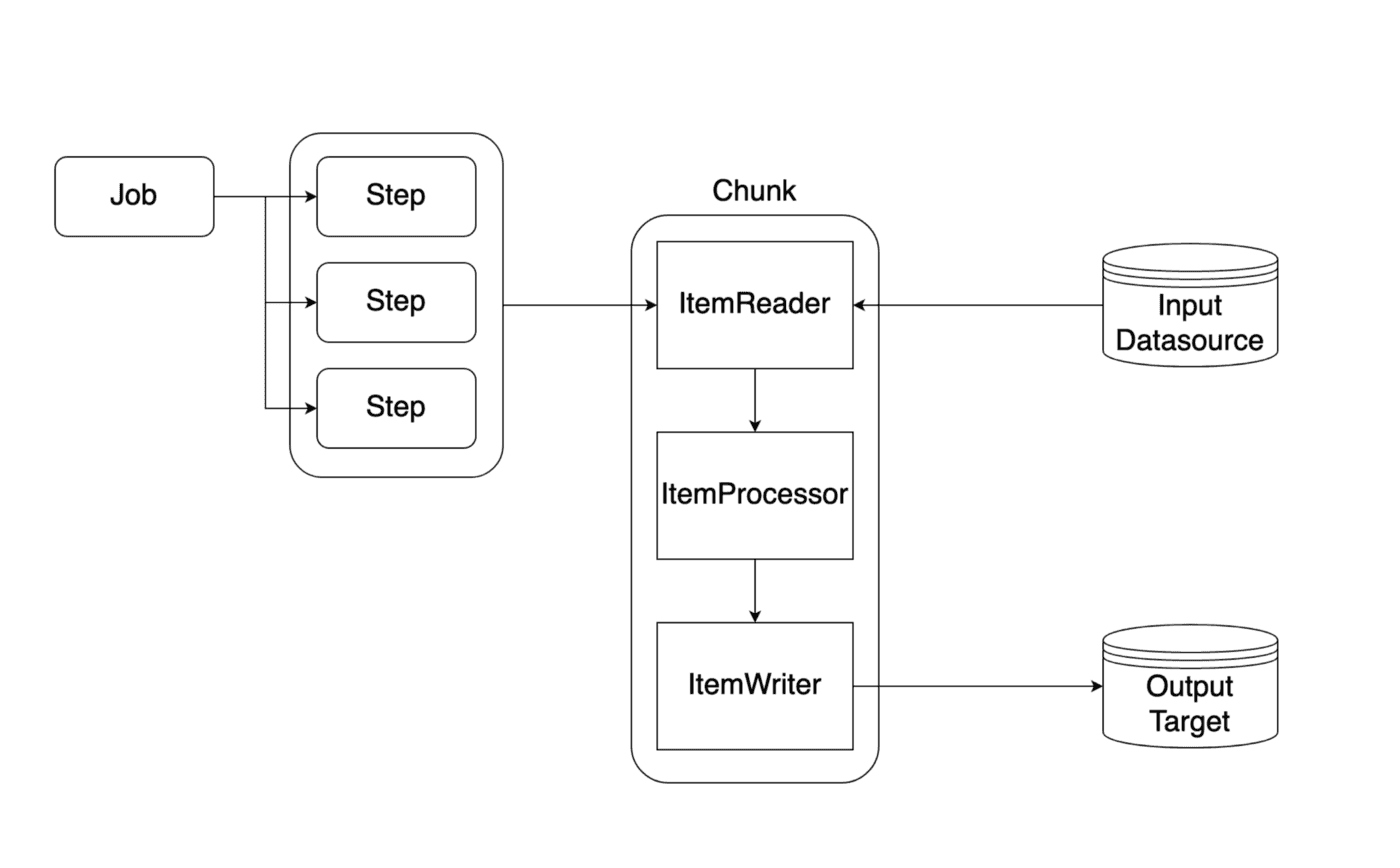
Job
- Job은 배치 처리 과정을 하나의 단위로 만들어 포현한 객체
- 스프링 배치에서 Job 객체는 여러 Step 인스턴스를 포함하는 컨테이너
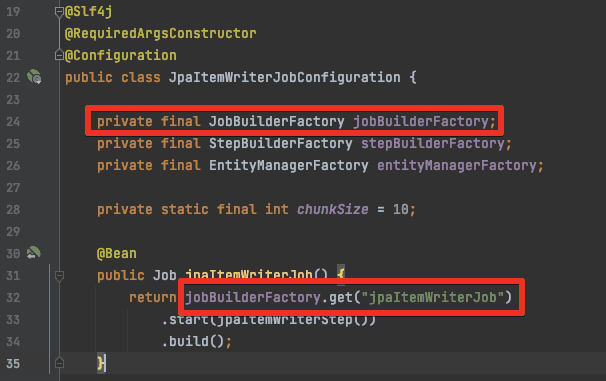
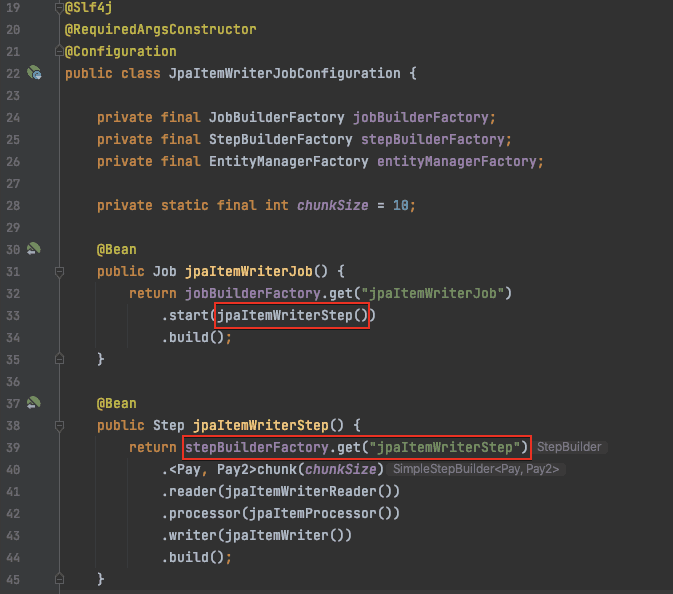
- JobBuilderFactory로 Job을 만들 수 있다
Step
- Step은 실직적인 배치 처리를 정의하고 제어 하는데 필요한 모든 정보가 있는 도메인 객체. Job을 처리하는 실질적인 단위
- 모든 Job에는 1개 이상의 Step이 있어야 한다.
- StepBuilderFactory로 Step을 만들 수 있다
ItemReader
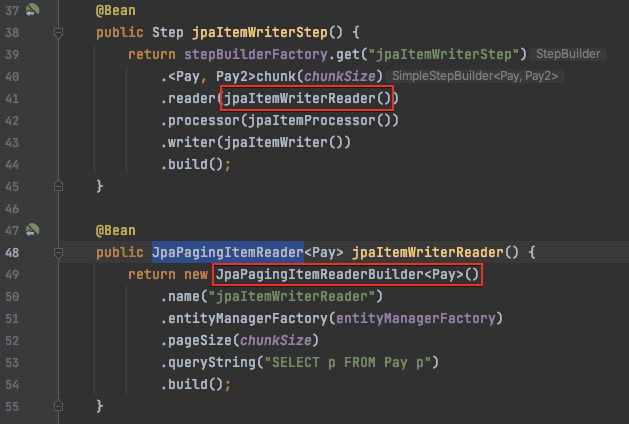
- ItemReader는 Step의 대상이 되는 배치 데이터를 읽어오는 인터페이스. File, Xml Db등 여러 타입의 데이터를 읽어올 수 있다.
ItemProcessor (Optional)
- ItemReader로 읽어 온 배치 데이터를 변환하는 역할
- 비즈니스 로직의 분리 : ItemWriter는 저장 수행하고, ItemProcessor는 로직 처리만 수행해 역할을 명확하게 분리

ItemWriter
- ItemWriter는 배치 데이터를 저장. 일반적으로 DB에 저장
- ItemWriter도 ItemReader와 비슷한 방식으로 구현. 제네릭으로 원하는 타입을 받고 write() 메서드는 List를 사용해서 저장한 타입의 리스트를 매개변수로 받는다.
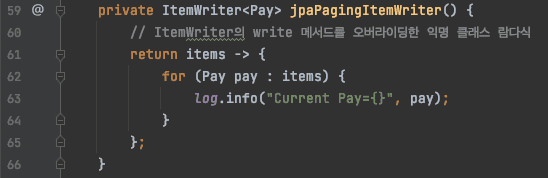
- Entity로 등록된 객체라면 ItemWriter를 구현한 JpaItemWriter클래스를 사용하여 편리하게 처리할 수 있다.


스프링 배치의 메타 데이터
- 이전에 실행한 Job
- 최근 실패한 Batch Parameter, 성공한 Job
- 다시 실행시 어디서 부터 시작하면 되는지에 대한 정보
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공한 Step과 실패한 Step들은 어떤것들이 있는지등
BATCH_JOB_INSTANCE
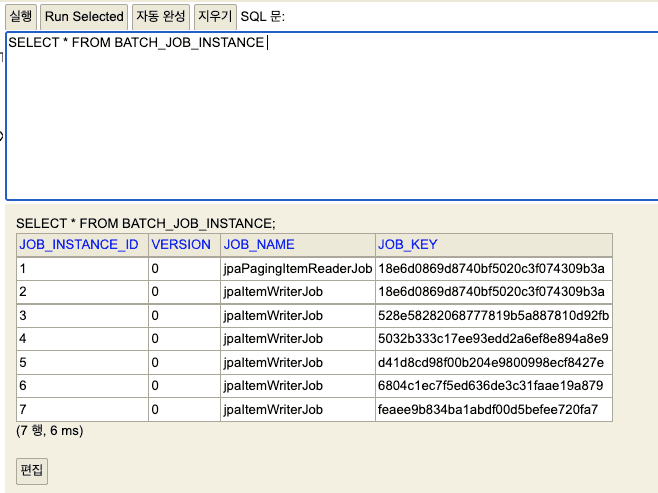
- 하나의 Job 실행 단위
- 동일한 Job이 Job Parameter가 달라지면 그때마다 생성되며, 동일한 Job Parameter는 여러개 존재할 수 없다.
BATCH_JOB_EXECUTION
- JOB_INSTANCE (부모) - JOB_EXECUTION (자식)
- 부모 JOB_INSTANCE가 성공/실패했던 모든 내역을 가지고 있다
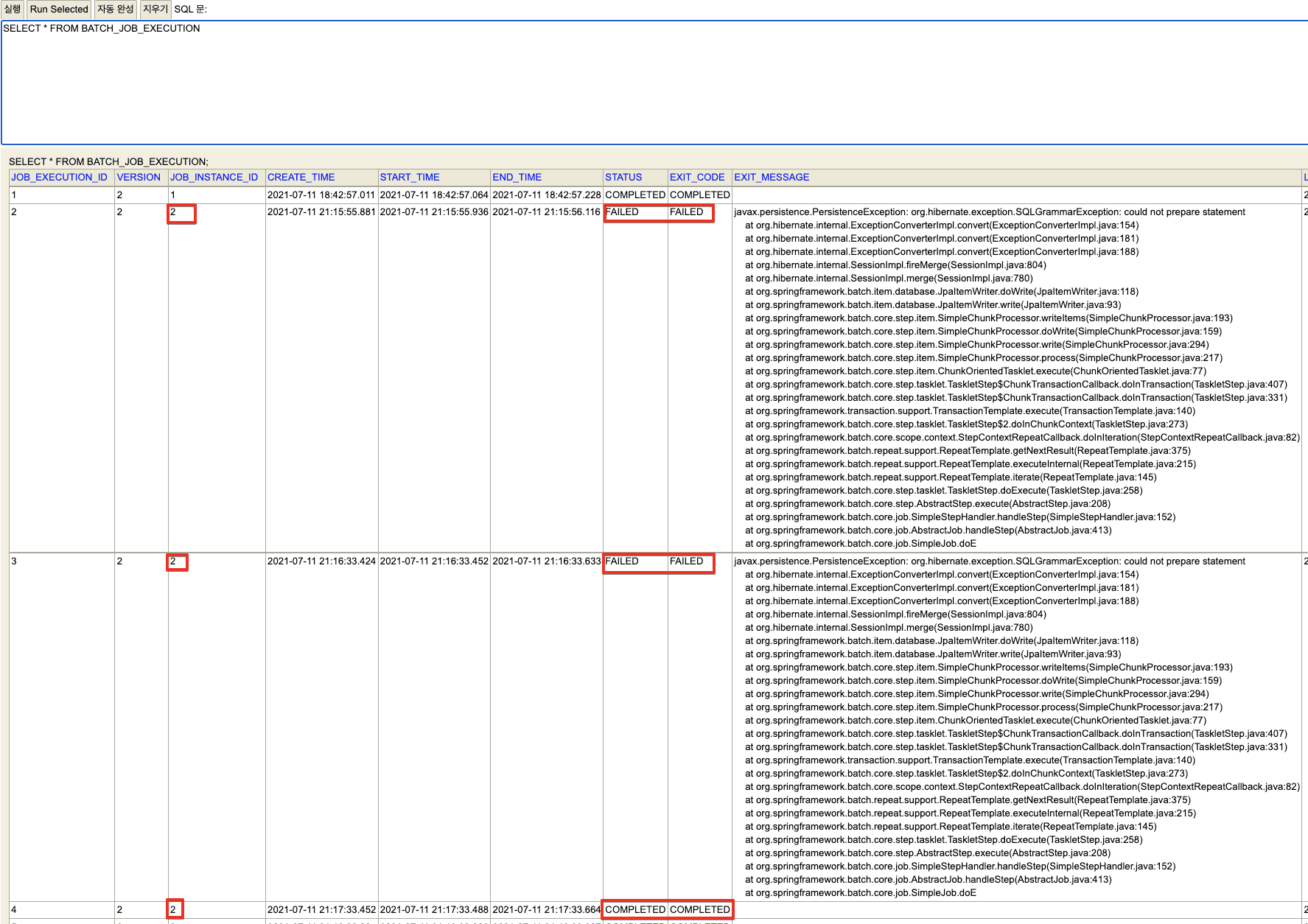
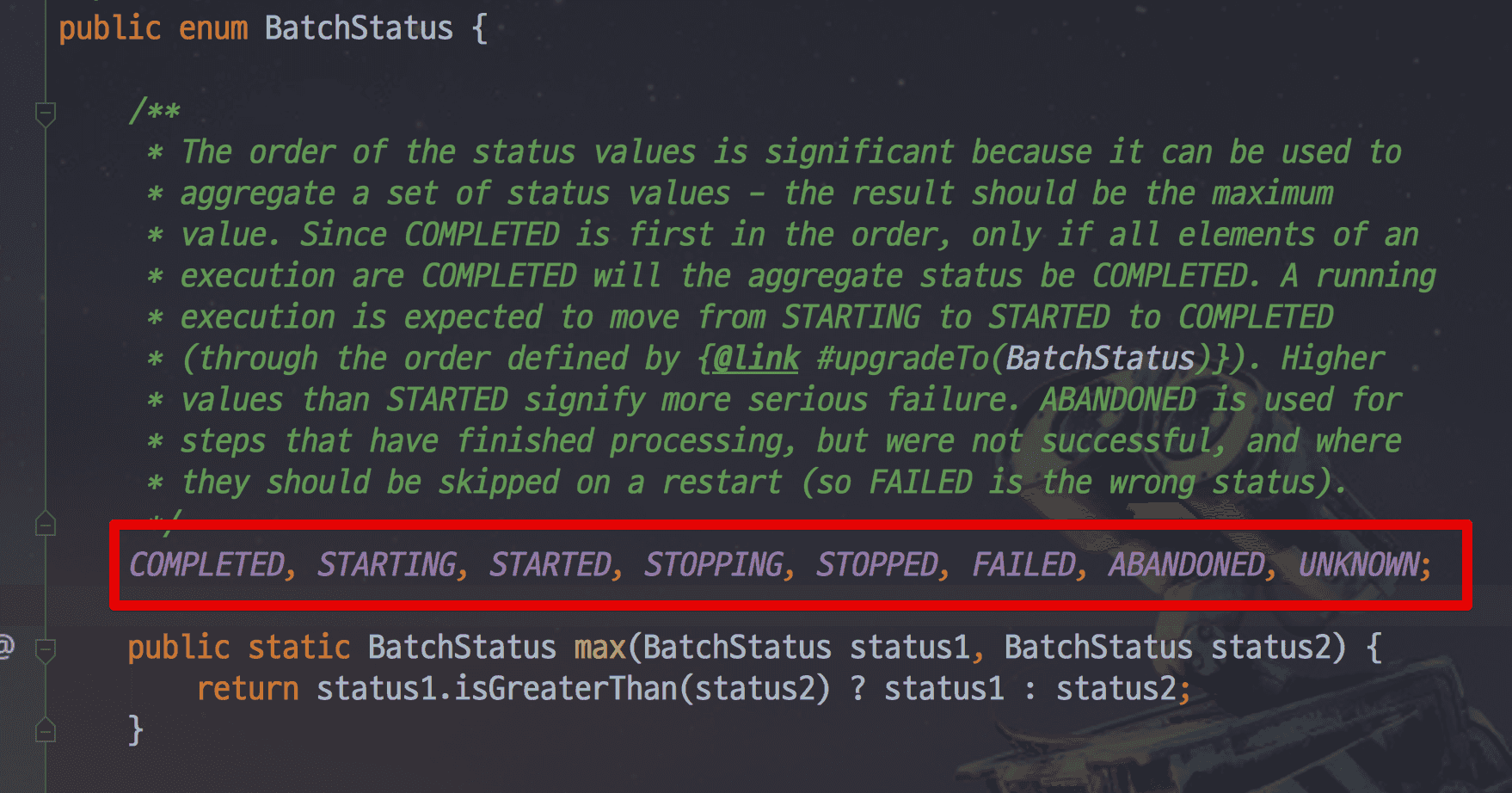
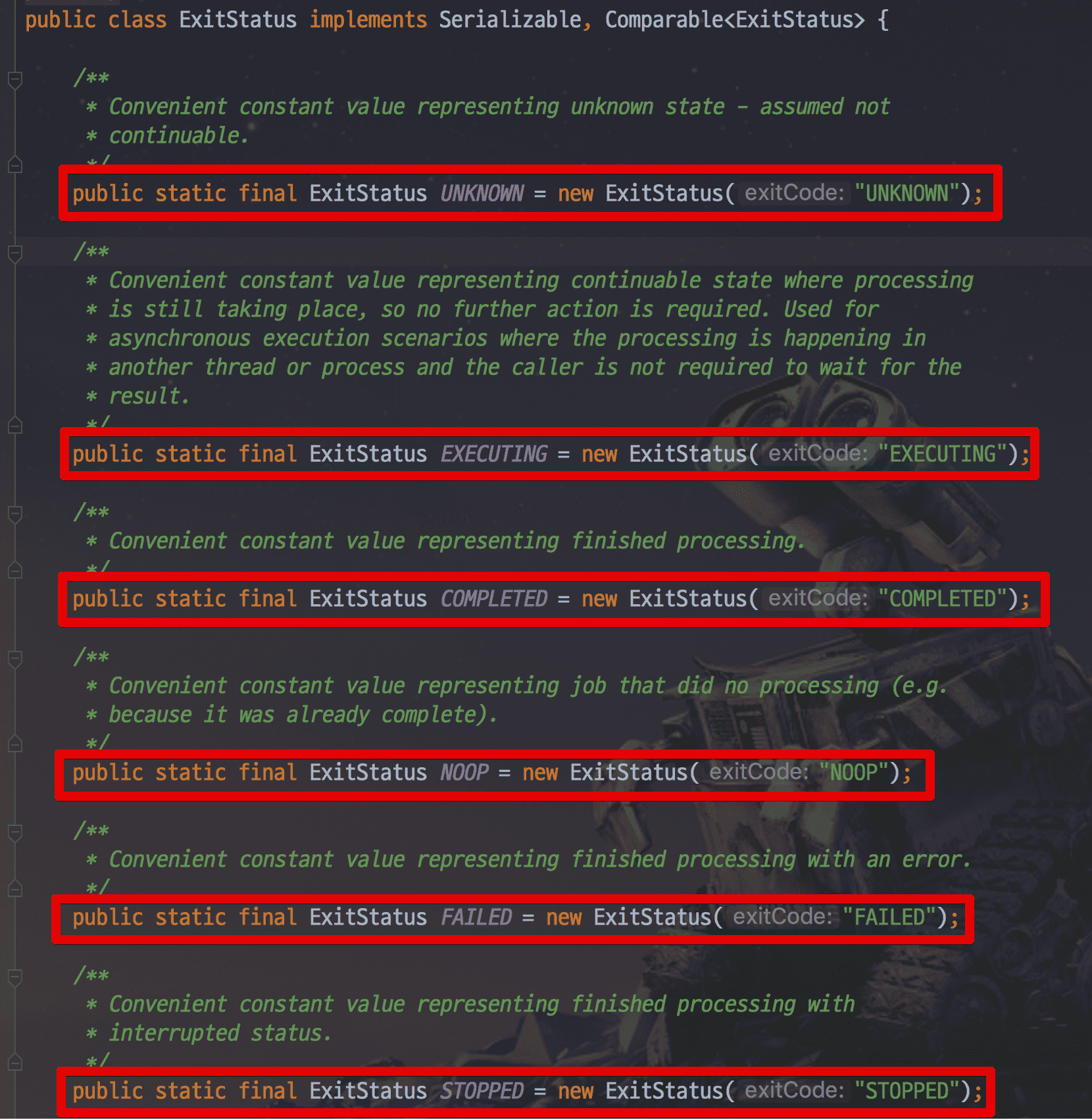
- status : Job또는 Step의 실행 결과를 기록. BatchStatus Enum에서 확인 가능
- exit_code : Job또는 Step의 실행 후 상태. ExitStatus 클래스에서 확인가능 (Enum 아님)
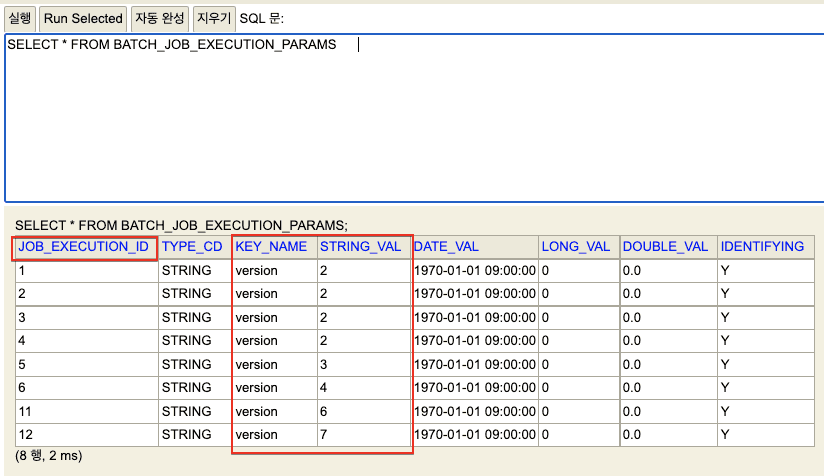
BATCH_JOB_EXECUTION_PARAM
- BATCH_JOB_EXECUTION 테이블이 생성될 때 입력 받은 Job Parameter 확인가능
BATCH_STEP_EXECUTION
- Job에 JobExecution Job실행 정보가 있다면 Step에는 StepExecution이라는 Step 실행 정보를 담는 객체가 있다. (거의 비슷)
JobParameter와 Scope
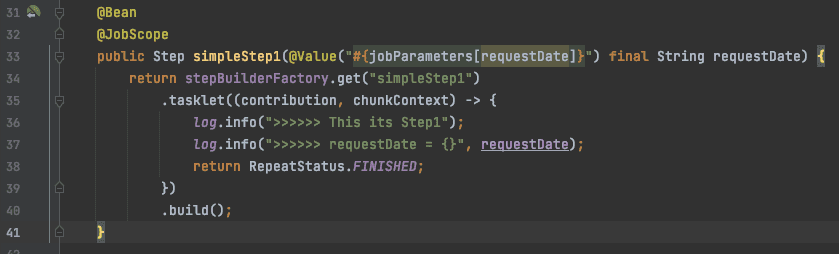
- SpEL로 선언해서 사용
- @Value(”#{jobParameters[파라미터명]}“)
- JobParameter를 사용하려면 배치 스코프를 @JobScope나 @StepScope로 반드시 조정해야한다 (일반 singleton Bean으로 생성할 경우 ‘jobParameters’ cannot be found 에러가 발생)
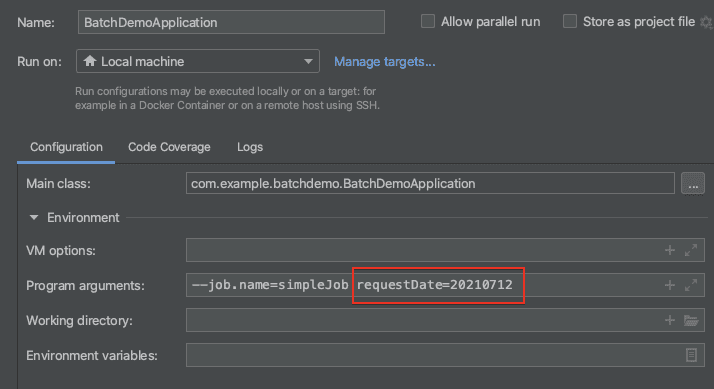
JobScope & StepScope
- Job, Step의 실행시점에 해당 컴포넌트를 Spring Bean으로 생성한다
- JobParameter의 Late Binding이 가능하다
- Application 실행시점이 아니라 비지니스 로직 처리단계에서 Job Parameter 할당 가능
- 동일 한 컴포넌트를 병렬 혹은 동시에 사용할 때 유용
- 각각의 Job, Step에서 별도의 Tasklet을 생성하고 관리하기 때문에 서로의 상태를 침범할 일이 없다
Chunk
- 각 커밋 사이에 처리되는 row 수
- Chunk 단위로 트랜잭션
- 중간에 실패할 경우엔 해당 Chunk 만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영됨
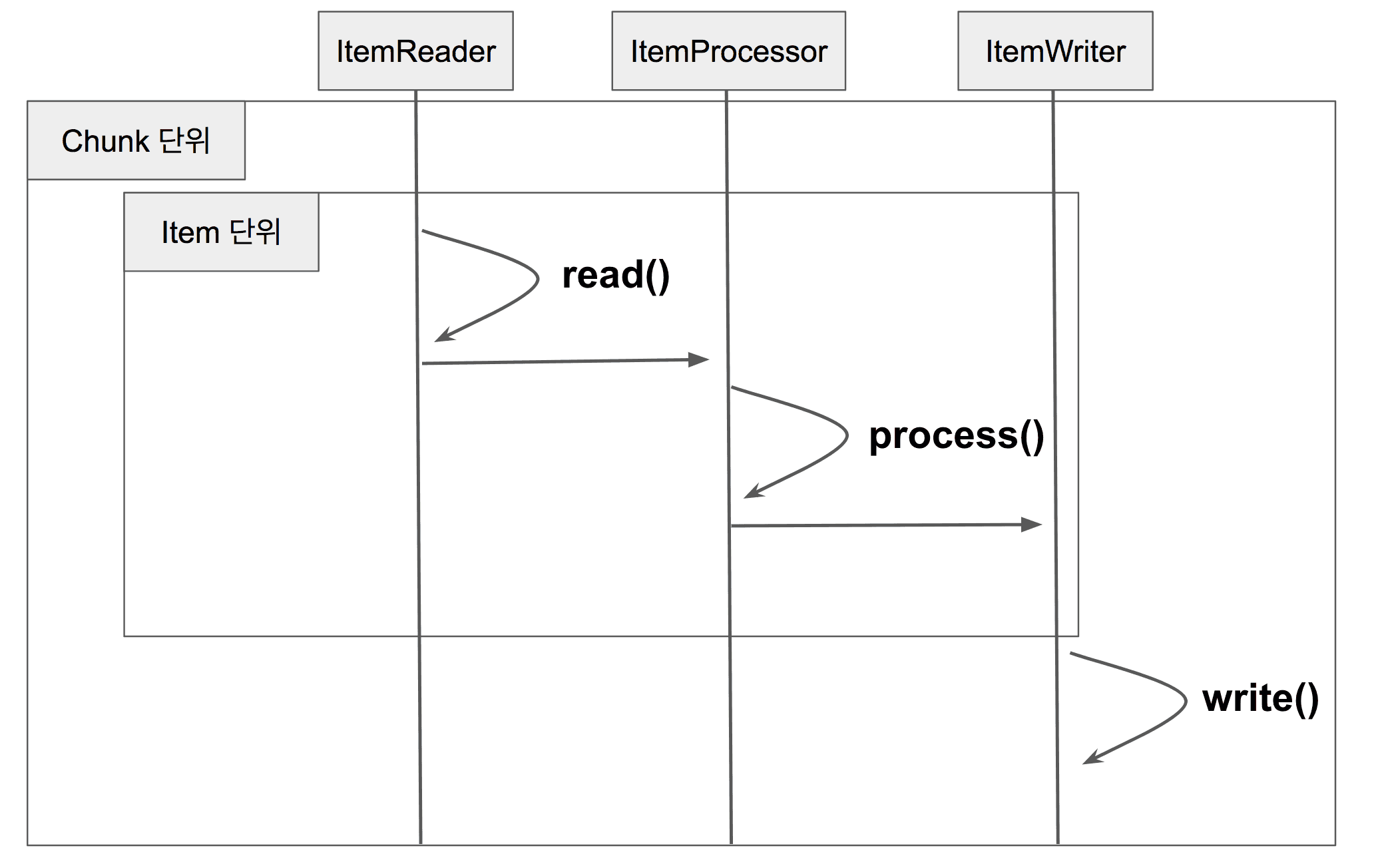
Page Size vs Chunk Size
- Chunk Size: 한번에 처리될 트랜잭션 단위
- Page Size: 한번에 조회할 Item의 양
만약 PageSize가 10이고, ChunkSize가 50이라면
- ItemReader에서 Page 조회가 5번 일어나면 1번 의 트랜잭션이 발생하여 Chunk가 처리
- 한번의 트랜잭션 처리를 위해 5번의 쿼리 조회가 발생하기 때문에 성능상 이슈가 발생할 수 있다
- PageSize와 ChunkSize는 일치시키는 편이 좋다
적정한 Chunk SIze?
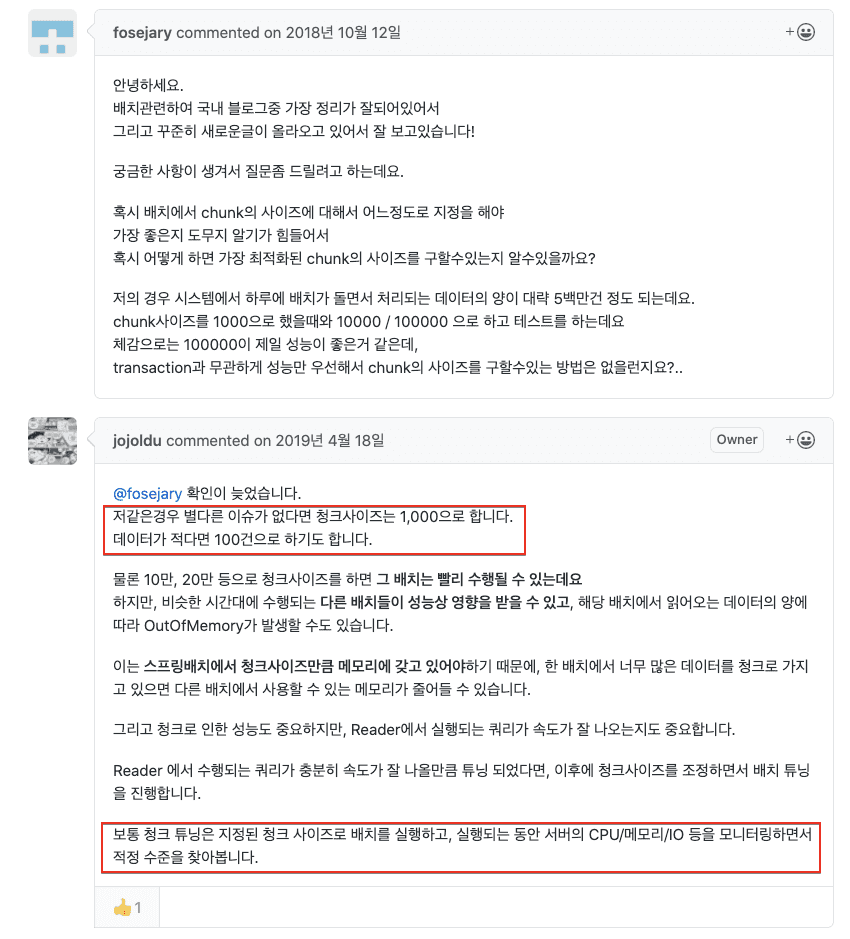
- Chunk Size를 아주 크게 하면 그 배치는 빨리 수행될 수 있지만
- 다른 배치들이 성능상 영향을 받을 수 있고
- OutOfMemory가 발생할 수도 있다
- 배치가 실행되는 동안 서버의 CPU/메모리/IO 등을 모니터링 하면서 적정 수준을 찾아야한다
더 공부해야 할 것
Spring Batch 관리 도구로서의 Jenkins - https://jojoldu.tistory.com/489
Spring Reactive (Webflux, Mono)
참고자료
- 이동욱님 Spring Batch 가이드 시리즈 - https://jojoldu.tistory.com/324?category=902551
- Spring Batch, 처음부터 시작하기 - https://medium.com/myrealtrip-product/spring-batch-처음부터-시작하기-3c6a5db0646d
- 우아한스프링배치 - https://youtu.be/_nkJkWVH-mo
- 처음으로 배우는 스프링 부트 2